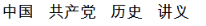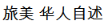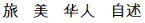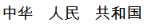and
and  simplify to
simplify to 
When Chinese language terms and phrases are searched in SirsiDynix Symphony, the following keyword search strategies are applied.
Order of Translation
Chinese is translated from traditional to simplified and indexed as Simplified Chinese.
The order of the translation (traditional to simplified) was chosen because one traditional character should lead to one simplified character, or at least less simplified characters, but one simplified character could lead to many traditional characters. Therefore, it would not be possible to index properly in traditional Chinese going from simplified.
For example, the traditional characters and simplify to
The traditional characters and simplify to  .
.

If there is no simplified equivalent of the traditional character, then the traditional character will be indexed untranslated.
Chinese Segmented (Keyword) Search
The segmentation will take place before the strings are converted to simplified Chinese to ensure correct treatment of the meaningful units in traditional Chinese strings.
SirsiDynix Symphony’s segmented searching is the default keyword search mode for systems configured with Unicode. The main concept behind the search strategy is to extract meaningful combination of Chinese characters from the search string and use them to construct a keyword search request rather than looking for an exact match of the search string.
For example, when the typed search string is “Chinese History,”  (zhong guo li shi), the keyword search will return hits for records containing Chinese modern history, Chinese social history, and so on.
(zhong guo li shi), the keyword search will return hits for records containing Chinese modern history, Chinese social history, and so on.
SirsiDynix Symphony’s segmented Chinese keyword searching is achieved by breaking up strings of Chinese characters into meaningful units or segments. SirsiDynix Symphony derives these segments by separating the search string into individual Chinese characters, and then moving from left to right rejoining these characters into longest possible meaningful sub-units based on the entries found in the Guojia Biaozhun Kuozhan (GBK) lexicon provided by Bejing Library and converted to Unicode.
The string (Chinese history) segments into two units  and
and 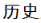 . This segmentation technique is applied to the data in the MARC fields when a record is indexed and when a search string is typed in WorkFlows or e–Library.
. This segmentation technique is applied to the data in the MARC fields when a record is indexed and when a search string is typed in WorkFlows or e–Library.
A segmented keyword search returns a hit whenever the segmented representation of the data in the target field contains all of the units in the segmented representation of the search term and the units occur in the same order, but not necessarily next to each other.
For instance, can match 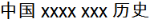 , but not
, but not 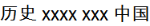 .
.
If the typed search string is (Chinese history) and is typed as the search term for a title search, it will be segmented into and . The search will return all records whose segmented title data includes both and in the following order.
|
Title String |
Segmented String |
|
|
|
|
|
|
|
|
|
The search term won’t match  (history of central republic of Africa) even though there the characters are in the target. This is because the segmented form of the title does not contain both the meaningful units.
(history of central republic of Africa) even though there the characters are in the target. This is because the segmented form of the title does not contain both the meaningful units.
|
Title String |
Segmented String |
|
|
|
In the previous example the segmentation is different because there are characters separating the characters 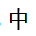 and
and  .
.
It is important to note that even though two or more characters may form a meaningful unit, adjacency is not sufficient to isolate them as a unit; it will depend on where they occur in relation to other characters in the string.
For example, the search term  (Chinese people) is a valid segmented unit but will only match target fields containing if it is a meaningful unit in the target context.
(Chinese people) is a valid segmented unit but will only match target fields containing if it is a meaningful unit in the target context.
|
Title String |
Segmented String |
Match |
|
|
|
Yes |
|
|
|
No |
Even though the string 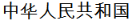 (People’s Republic of China) contains , it is not a match for the term
(People’s Republic of China) contains , it is not a match for the term  which will have been segmented and indexed as
which will have been segmented and indexed as 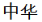 (China)
(China)  (people)
(people)  (republic). The string is not a meaningful unit in this context. Another example of differing contexts is the search string
(republic). The string is not a meaningful unit in this context. Another example of differing contexts is the search string  (standard Chinese) will not match
(standard Chinese) will not match  , even though both terms contain the characters .
, even though both terms contain the characters .
Phrase Searching
The Chinese phrase search essentially treats the search string as a non-broken unit and will only match the text that contains the search string as a whole.
For example, a phrase search for will return a hit for 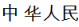 , whereas a segmented search will not. The only requirement for a hit for the phase search is that the target must contain all of the characters, in the order presented, and they must be adjacent.
, whereas a segmented search will not. The only requirement for a hit for the phase search is that the target must contain all of the characters, in the order presented, and they must be adjacent.
PinYin Search
If the system is configured to use Chinese language, SirsiDynix Symphony supports both the segmented and phrase search modes using full and abbreviated PinYin (Romanized version of Chinese) search strings as well as Chinese characters.
The PinYin is entered in a special subfield A which then gets converted into a “pinyin initials string,” but this only happens if the PinYin is in a subfield A of a tag that is marked as a SINO tag. Headings are built differently for tags that are marked as SINO tags. This processing only applies to Chinese formats, not MARC21 formats.
Once the PinYin has been converted, the search string is passed for segmentation as described previously.
The SirsiDynix Symphony software uses rules to derive the most likely Chinese string, given that there is not a one-to-one relationship between the PinYin words and the Chinese character set.
© 2006, 2014 SirsiDynix